
Có phải ít nhất 1 lần bạn đã từng thắc mắc rằng làm thế nào để Google có thể hiểu được toàn bộ nội dung trên website của bạn để index đúng không? Để làm được điều đó, Google đã sử dụng tới sự giúp sức của Crawler. Vậy Crawler là gì? Cùng tìm hiểu cách thức Crawler trong SEO chi tiết nhất trong bài viết dưới đây nhé!
Crawl là gì?
Crawling (thu thập thông tin) chính là quá trình khám phá của các công cụ tìm kiếm gửi thành nhóm Googlebot tìm kiếm nội dung và cập nhật mới trên website. Nội dung này có thể là website, hình ảnh, PDF, video. Tuy nhiên dù ở bất kể định dạng nào thì nội dung cũng sẽ được phát hiện bởi các liên kết.
Googlebot sẽ tìm nạp 1 vài website sau đó dựa theo các liên kết để tìm ra những URL mới. Khi đó quá trình thu thập thông tin có thể tìm kiếm thêm nội dung mới và thêm chúng vào chỉ mục có tên là Caffeinel. Đây là cơ sở dữ liệu về URL lớn nhất được phát hiện thông qua liên kết và sự tìm kiếm của người dùng.
Web Crawler là gì?
Web Crawler là phần mềm thiết kế ra với mục đích duyệt website trên mạng World Wide Web theo hệ thống và thu thập được toàn bộ thông tin của website đó về cho công cụ tìm kiếm.
Việc làm này không chỉ mang đến khả năng lưu chỉ mục của website vào bộ cơ sở dữ liệu Search Engine mà còn giúp công cụ tìm kiếm đưa ra những đánh giá chính xác nhất về trang web được thu thập dữ liệu.
Mô hình của Web Crawler bao gồm:
- URL khởi đầu
- Dùng HTML protocol để lấy website
- Trích xuất link và lưu trữ link trong queue
- Lặp lại các bước 2, 3 nhiều lần

Một số module quan trọng của crawler:
- Fetch module có thể lấy các trang web
- URL Frontier chứa danh sách có các URL chưa được lấy
- Parsing module trích xuất văn bản, link từ tweb đã lấy.
- DNS resolution module giúp xác định địa chỉ của server website
- Duplicate elimination module giúp loại bỏ các URL trùng lặp.
Cơ chế hoạt động của Web Crawler là gì?
Với tính năng khám phá, tìm hiểu thông tin trên các trang web công khai hiện nay thì cơ chế hoạt động của Web Crawler chính là thu thập thông tin hữu ích sau đó theo dõi website để dò theo liên kết có trong những trang web đó.
Việc này giống như việc duyệt nội dung trên website. Web Crawler tiến hành thu thập dữ liệu trên web bằng việc đi lần lượt từng liên kết và đưa dữ liệu về máy chủ Search Engine. Quá trình thu thập dữ liệu, thông tin này sẽ bắt đầu từ danh sách các địa chỉ website bất kỳ. Thường những web đó sẽ lưu từ những lần tìm kiếm trước hoặc do chủ sở hữu wseb gửi tới. Sau đó sẽ tiến hành thu thập dữ liệu nhưng web có liên quan và thường ưu tiên những liên kết mới.
Phần mềm này còn xác định được những website cần thu thập thông tin, báo cáo tần suất trang cần tìm nạp từ mỗi web khác nhau. Crawler không hoạt động tự động và hạn chế chịu sự can thiệp của con người.
Sau khi đã thu thập đầy đủ dữ liệu thì các web Crawler sẽ tổng hợp dữ liệu đó với dữ liệu ngoài trang để gửi về ngân hàng dữ liệu chờ xét duyệt.
Sự khác biệt giữa crawling và indexing
Crawling (thu thập thông tin) là việc khám phá những trang và liên kết dẫn tới trang nhiều hơn, nhất là những liên kết mới để thu thập dữ liệu, thông tin. Còn Indexing (lập chỉ mục) là quá trình phân tích, lưu trữ, sắp xếp nội dung và kết nối giữa các trang web với nhau.
Một số phần của lập chỉ mục có vai trò thông báo tới người dùng cách mà công cụ tìm kiếm thu thập thông tin, dữ liệu.

Cách bot công cụ tìm kiếm crawl website
Mạng internet ngày càng phát triển và không ngừng thay đổi, mở rộng. Vì thế để có thể nắm được tổng thể các website trên internet nên các web crawlers sẽ bắt đầu với những danh sách các URL biết trước. Sau đó chúng thu thập dữ liệu webpage từ các URL đó. Từ những page này chúng sẽ tìm thấy các liên kết URL khác và thêm vào danh sách để thu thập thông tin tiếp theo.
Với số lượng rất nhiều website trên internet hiện nay thì việc lập chỉ mục để tìm kiếm và quá trình này diễn ra gần như vô thời hạn. Tuy nhiên những web crawler sẽ tuân thủ theo chính sách nhất định giúp chúng có nhiều lựa chọn hơn về việc thu nhập dữ liệu web nào, trình tự và tần suất ra sso để dễ dàng cập nhật nội dung.
Hầu hết các web crawler sẽ không thu thập toàn bộ thông tin có sẵn công khai trên internet mà và không nhắm vào bất kỳ mục đích gì. Chúng sẽ chỉ quyết định trang nào sẽ thu thập dữ liệu đầu tiên dựa vào số lượng các trang đã liên kết lên trang đó, lượng người dùng truy cập và những yếu tố biểu thị khả năng cung cấp thông tin khác.
Nếu website được nhiều trang web khác trích dẫn, có lượng truy cập cao thì chứng tỏ trang web đó sẽ chứa thông tin chất lượng, hữu ích, có thểm quyền nên các công cụ tìm kiếm sẽ tiến hành index nhanh chóng.
Revisiting webpages
Revisiting webpages là quá trình web crawlers truy cập lại các trang theo định kỳ sau đó index các phần content mới được update trên web, xóa hoặc di chuyển chúng tới các vị trí mới.
Yêu cầu về Robots.txt
Web crawlers có quyền quyết định những trang web nào sẽ được thu thập thông tin dựa trên giao thức robots.txt. Tệp thông tin này sẽ được kiểm tra từ trang lưu trữ. Đây là tệp văn bản chỉ định những quy tắc cho bất kỳ bot nào truy cập vào website hoặc ứng dụng đã được lưu trữ.
Tất cả các yếu tố này sẽ có trọng số khác nhau tùy thuộc vào những thuật toán độc quyền mà mỗi công cụ tìm kiếm tự xây dựng cho họ. Tuy nhiên mục tiêu cuối cùng của chúng là giống nhau, đều là tải xuống và được index nội dung từ các trang web.

Những tên gọi của web crawler
Web crawler còn được biết đến với những tên gọi như bot, robot, ant, worm, spider,… Cùng tìm hiểu những tên gọi khác của chúng ngay sau đây nhé!
Tên gọi Ant là gì?
Ant là một trong những tên gọi được sử dụng khá phổ biến và dựa trên các lưu thông tin của website và các hoạt động chung của web crawler. Mỗi khi di chuyển thì con kiến sẽ tiết ra chất pheromone để lưu lại đường chúng đã đi qua. Việc đánh dấu liên kết của Ant cũng tương tự như vậy.
Cách gọi Crawler là gì?
Crawler laà cách gọi theo đúng chức năng của web crawler. Tên gọi này dùng để mô tả hành động truy cập và thu dữ liệu của web crawler trên website giống như con bọ đang bò trên trang web đó.
Bot là gì?
Bot hay còn gọi là Internet Bot. Đây là phần mềm ứng dụng chạy tự động trên nền tảng internet web robot nên thực hiện được các công việc đơn giản và lặp đi lặp lại theo hệ thống cho người sử dụng.
Spider nghĩa là gì?

Spider là cách gọi hình tượng hóa của web crawler. Tên gọi này bắt nguồn từ nguyên lý hoạt động và lưu trữ thông tin của web crawler và chúng giống hoạt động của 1 con nhện. Chúng sẽ bắt đầu từ website bất kỳ sau đó len lỏi vào từng ngóc ngách của trang và truy cập từng liên kết mà trang đó cung cấp.
Chúng sẽ đánh dấu những liên kết đã truy cập sau đó nối chúng với các trang có link giống trang gốc như tạo 2 sợi tơ liên kết 2 trang web với nhau. Từ 1 trang web ban đầu thì Spider có thể kết nối thêm được rất nhiều website khác như một hình mạng nhện đích thực.
Crawl có thể tìm thấy tất cả thông tin của bạn không?
Nếu bạn sở hữu 1 website thì có thể kiểm tra lại xem có bao nhiêu trang đã nằm trong chỉ mục. Điều đó sẽ giúp bạn kiểm soát được trang đã được lập chỉ mục trên Google nhanh chóng, dễ dàng hơn.
Bạn có thể kiểm tra bằng cách tìm kiếm “site:domain.com”. Kết quả trả về chính là những website đã được lập chỉ mục trên Google.
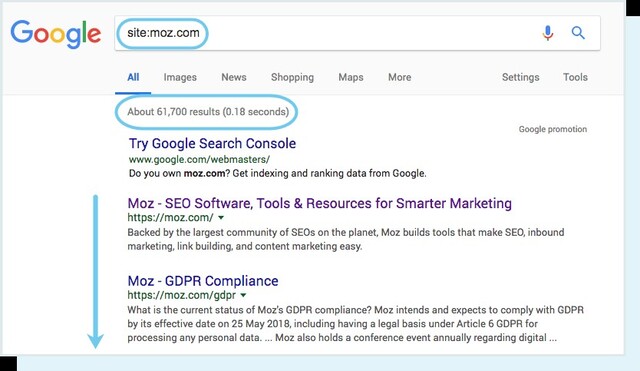
Số lượng kết quả mà Google trả về có thể không chính xác tới 100% nhưng chắc chắn sẽ mang lại cho bạn những thông tin cực kỳ hữu ích về tình trạng lập chỉ mục trên website của mình.
Nếu muốn có kết quả chính xác hơn thì bạn nên dùng báo cáo trạng thái lập chỉ mục ở Google Search Console. Bạn chỉ cần đăng ký tài khoản tại đây và tìm thêm được nhiều thông tin đa dạng, hữu ích về website của mình trên công cụ này.
Nếu bạn không tìm được website của mình trong hệ thống kết quả tìm kiếm thì có thể do một số nguyên nhân sau:
- Website mới ra mắt và chưa được Google thu thập thông tin
- Website không có trang web khác liên kết tới
- Thanh điều hướng website của bạn khiến Googlebot thu thập dữ liệu khó khăn
- Website của bạn có chứa nhiều đoạn mã chặn robot thu thập dữ liệu
- Tên miền của bạn có thể đã bị Google phạt vì dùng chiến thuật spam.
Tại sao việc quản lý bot rất quan trọng đến việc thu thập dữ liệu web?
Bot Google được phân chia thành 2 loại là bot độc hại và bot an toàn. Những con bot độc hại sẽ gây ra cho website của bạn cực kỳ nhiều thiệt hại như: sự cố máy chủ, đánh cắp dữ liệu, trải nghiệm người dùng kém,…
Để ngăn chặn những con bot độc hại này thì bạn cần cho phép những con bot an toàn ví dụ như crawlers web truy cập vào thuộc tính web của mình.
Trên đây là những thông tin chi tiết nhất về Crawler. Chắc hẳn bạn đã hiểu rõ được Crawler là gì và tầm quan trọng của chúng trong các chiến dịch SEO website của doanh nghiệp. Hy vọng bài viết đã cung cấp cho bạn đọc những kiến thức hữu ích nhất. Trân trọng!